
7 Log Correlation Best Practices for Security
7 Log Correlation Best Practices for Security
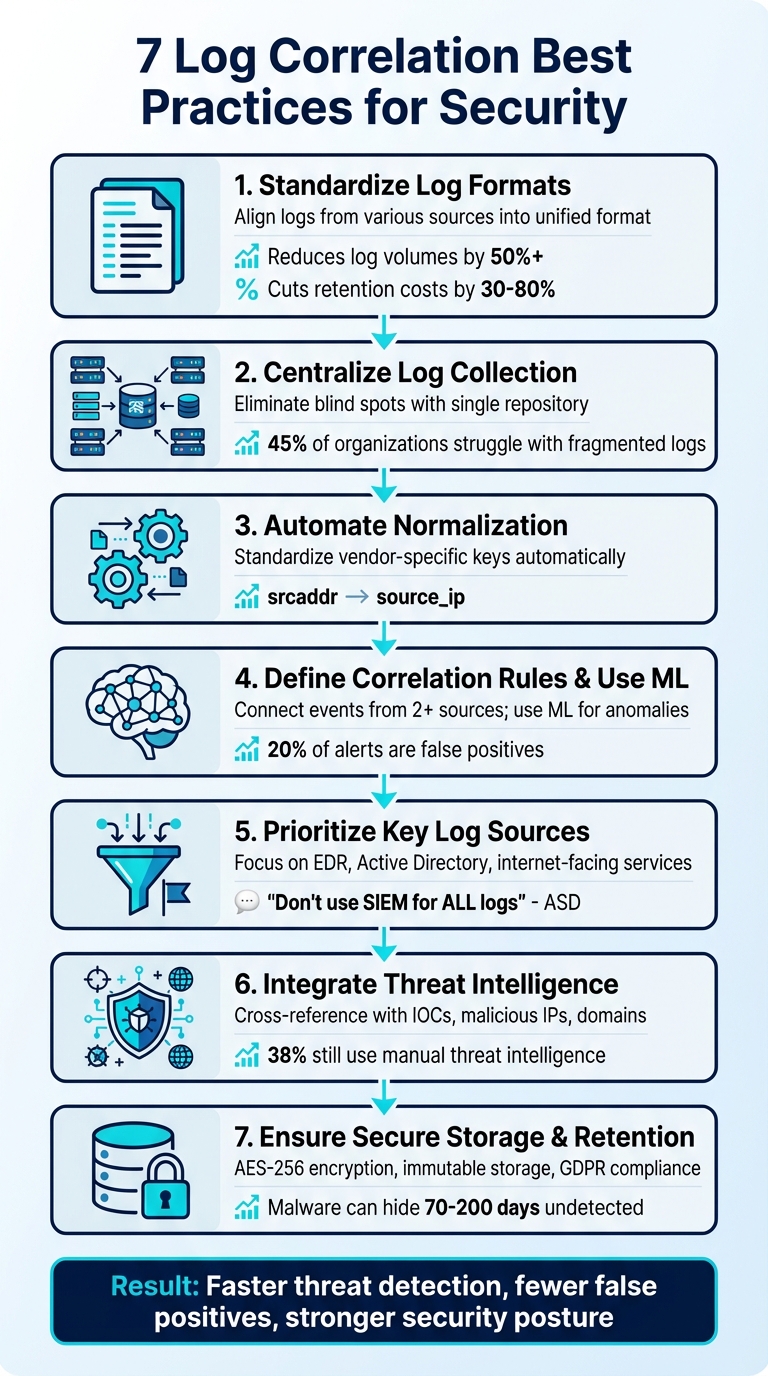
Log correlation is essential for identifying security threats hidden in the massive amounts of data organizations generate daily. By connecting events across systems, it helps uncover patterns and detect potential risks. Here’s a quick overview of the best practices to improve log correlation and strengthen your security operations:
- Standardize Log Formats: Align log structures from various sources (e.g., firewalls, servers) into a unified format for easier analysis and reduced storage costs.
- Centralize Log Collection: Combine all logs in one place to eliminate blind spots and improve visibility across systems.
- Automate Normalization: Use tools to standardize inconsistent log fields, enrich data, and reduce manual efforts.
- Define Correlation Rules & Use Machine Learning: Create rules to identify suspicious patterns and leverage machine learning for detecting anomalies.
- Prioritize Key Log Sources: Focus on critical logs (e.g., EDR, Active Directory) to avoid overwhelming volumes and improve detection accuracy.
- Integrate Threat Intelligence: Add external context (e.g., known malicious IPs) to logs for better threat assessment.
- Ensure Secure Storage & Retention: Encrypt logs, use tamper-proof storage, and retain data long enough for investigations.
These methods streamline threat detection, reduce false positives, and help security teams focus on real risks. Tools like LogCentral simplify implementing these practices by automating processes and ensuring compliance with regulations like GDPR.
Key takeaway: Centralize, standardize, and enrich your logs while using automation and prioritization to stay ahead of security threats.
7 Log Correlation Best Practices for Security Operations
How to use correlation rules for effective threat detection
1. Standardize Log Formats
Security teams often struggle to integrate logs from various sources like Windows Event Logs, VPC flow logs, and firewall outputs because they use different formats. Aligning these formats into a unified structure makes it easier to aggregate and correlate data across multiple systems.
By standardizing log formats into a common schema, key data points - such as IP addresses and user IDs - are consistently named. This allows security tools to seamlessly aggregate and correlate events without being tripped up by mismatched terminology [6]. Additionally, standardized logging removes irrelevant event codes, cutting down log collection volumes by over 50% [4]. With proper data tiering and lifecycle management, this can reduce retention costs by anywhere from 30% to 80% [4].
"Data normalization organizes log information into a structured format, making it easier to analyze and interpret." – Jeff Darrington, Director of Technical Marketing, Graylog [6]
Normalized logs are essential for linking related events, which helps reduce alert fatigue and improves threat detection [4][6]. Advanced functionalities like automated anomaly detection, risk scoring, and machine learning models also rely on consistent schemas to work effectively [6]. Without standardization, these capabilities lose their edge.
To achieve this, frameworks like Elastic Common Schema (ECS) or Graylog Extended Log Format (GELF) are highly recommended. They ensure consistent field naming and eliminate the need for manual mapping of relationships between systems [4][6]. Tools like LogCentral further simplify the process by automating log normalization during ingestion, converting diverse formats into structured data effortlessly. Standardized logs are the foundation for reliable multi-source event correlation, a key component of effective security monitoring.
2. Centralize Log Collection
Centralizing log collection takes the standardization of log formats to the next level, making it easier to identify connections across different systems. When logs are scattered - firewall logs in one place, application logs in another, and endpoint logs elsewhere - it creates blind spots that attackers can exploit. Imagine this: a failed login attempt on one system, followed by unusual file access on another. Individually, these events might seem harmless, but together, they could signal a coordinated attack. Without centralization, these connections are easy to miss.
45% of organizations struggle to quickly detect critical security incidents due to fragmented and unstructured logging practices [8]. By routing all logs to a single repository, you eliminate these blind spots. A unified log repository doesn't just improve visibility - it also speeds up incident investigations, giving security teams a clear, consolidated view of events. This approach works hand-in-hand with standardized log formats, offering a single source for efficient analysis.
"Centralizing access to security logs transforms fragmented monitoring data into actionable intelligence." – Microsoft [7]
Centralized systems also allow for extended log retention, which is crucial for investigating long-term threats. Advanced persistent threats (APTs), for example, can remain dormant for months before launching an attack. With extended retention, forensic teams can trace the initial access points of these threats. Microsoft has recognized this need, extending its standard audit log retention for Microsoft 365 customers to 180 days, with some logs now retained for up to two years [7]. This extended retention, paired with centralization, makes it easier to detect and analyze long-term attack patterns.
For seamless log forwarding, unified agents like Elastic Agent or Filebeat can automate the process [4][8]. Tools like LogCentral further simplify log management by offering native multi-tenancy and role-based access control (RBAC). This setup allows managed service providers (MSPs) and IT teams to oversee logs from multiple clients in one secure location, ensuring faster detection and stronger security measures [9].
3. Implement Automated Normalization
Automated normalization builds on centralized log collection by addressing inconsistencies in log formats. For instance, a firewall might log source IP addresses as srcaddr, AWS might use sourceIPAddress, and another system could label it as source.ip. Without automation, security teams would spend countless hours mapping these differences or risk overlooking critical connections.
Normalization engines simplify this process by applying predefined rules and regex to standardize vendor-specific keys into consistent field names. For example, variations of source IP addresses are unified under source_ip, while destination addresses become destination_ip. This approach eliminates the need for manual parsing of unstructured data and ensures all logs adhere to a standardized format[10][6].
In addition to normalization, automation can filter out irrelevant codes, reducing log volume and improving alert accuracy[4]. These processes also validate data integrity and enrich logs with extra context, such as geographic location, user identity, or threat intelligence[6][4]. This enrichment sharpens risk scoring and minimizes alert fatigue, ensuring that alerts are meaningful rather than overwhelming noise.
Using standard schemas like ECS or GELF enhances compatibility with third-party tools and allows access to pre-built detection rules. Platforms like LogCentral provide native mapping for integrations with services such as Cisco Meraki[6][4][10]. Similarly, tools like Coralogix use extension packages to automatically apply standardized keys across logs from AWS, Okta, and CrowdStrike[10]. By aligning data to a common schema, organizations unlock advanced detection rules and machine learning models - what Elastic describes as the "secret sauce" for cutting-edge security analytics[4].
This level of standardization is essential for accurate, real-time threat analysis across platforms. It also lays the groundwork for more precise correlation strategies, enabling security teams to act faster and more effectively.
4. Define Correlation Rules and Use Machine Learning
To enhance threat detection, it's not enough to just standardise and centralise your logs - you also need well-defined correlation rules. Once logs are normalised, these rules help connect events from multiple sources to uncover potential threats. For a rule to be effective, it should involve at least two log sources to pinpoint genuine threat scenarios [11][12]. For instance, a brute force detection rule might flag a TargetUserName triggering more than 10 failed Windows logon attempts (Event ID 4625) within a 5-minute interval [13]. This simple frequency-based logic monitors patterns that suggest suspicious activity.
Some scenarios call for more advanced rules, where events must occur in a specific order. In 2024, security teams uncovered the CVE-2023-22518 Confluence exploit by correlating a POST request to a vulnerable endpoint (with status codes 200, 302, or 405) and a suspicious process creation - like cmd.exe or powershell.exe launched by tomcat.exe - all happening within 10 seconds [13]. Another example uses value count logic: a rule might identify BloodHound enumeration scans by spotting a single user accessing at least four unique high-privilege Active Directory groups (e.g., Administrators or Remote Desktop Users) within a 15-minute window [13].
"Correlation allows you to apply intelligence to the logs, typically with if/then logic statements."
- Stephen Perciballi, Palo Alto Networks [5]
While rule-based logic is effective, machine learning (ML) takes detection to the next level by identifying anomalies that don’t follow predefined patterns. Rule-based methods are great for predictable threats, but ML engines excel at spotting the unexpected. These engines typically need about two weeks to establish a baseline and detect unusual activity in high-volume data [15]. This is especially important given that up to 20% of incident alerts are false positives, according to one-third of cybersecurity professionals [2].
To increase the precision of your alerts, start by enabling all vendor-provided correlation rules and then fine-tune them. For example, you can filter out known safe activities, like internal network scans or authorised administrative subnet traffic [5]. Additionally, always define a group-by field, such as TargetUserName or ComputerName, to ensure correlation logic targets specific entities rather than applying broadly across the environment [13][14]. This approach helps cut down on unnecessary alerts and keeps the focus on real threats.
5. Prioritize Key Log Sources
Gathering every single log might sound thorough, but it often leads to overwhelming data volumes, skyrocketing storage costs, and buried critical alerts. The Australian Signals Directorate sums it up well: "The authoring agencies strongly discourage using a SIEM as the central repository for all logs. A SIEM should only be used for centralisation of specific security logs according to the organisation's risk profile" [16]. In other words, focus on the logs that truly matter - those that reveal genuine threats.
The idea here builds on earlier discussions about standardized and centralized logging: by narrowing your focus to high-value sources, you can significantly improve threat detection. Start by asking yourself a key question: If this system were compromised, could the organisation still function? This helps identify high-priority log sources. These typically include:
- Endpoint Detection and Response (EDR) logs: Track process creation and script execution, making them essential for spotting suspicious activity.
- Active Directory servers: Monitor credential validation and privilege escalation, key indicators of potential breaches.
- Internet-facing services: Logs from VPNs, firewalls, and web proxies are critical as they often expose attempts at phishing or credential abuse.
A focused approach like this not only improves visibility but also sets the stage for refining your log collection and analysis strategies.
Take the Volt Typhoon campaign from mid-2021 as an example. This operation targeted critical infrastructure organisations and relied heavily on "Living off the Land" (LOTL) techniques. Attackers used native Windows tools like PowerShell, vssadmin, and ntdsutil.exe to copy Active Directory databases and steal hashed credentials [3]. Without prioritised logging - such as monitoring domain controller logs or EDR data - detecting these subtle, yet dangerous, activities would have been nearly impossible.
If your organisation operates in cloud or OT (Operational Technology) environments, your priorities will shift slightly. For cloud setups, focus on control plane operations, including API calls, administrative configuration changes, and updates to security principals [3][16]. In OT environments, give attention to safety-critical devices and internet-facing systems. Since many OT devices lack the processing power for robust logging, network sensors can step in to generate logs from traffic payloads [3][16]. Start with these critical sources and expand only as your analytical capabilities grow [16].
To manage this effectively, consider using a dedicated log management tool like LogCentral. Tools like this help filter and correlate high-value logs, keeping your security monitoring laser-focused on actionable insights.
6. Integrate Threat Intelligence and Context
Even the best-prioritised logs can overlook critical threats when viewed in isolation. That’s where external threat intelligence feeds come into play. They add essential context, turning raw log data into actionable security insights. By cross-referencing your internal logs with known Indicators of Compromise (IOCs) - like malicious IP addresses, domains, URLs, or file hashes (MD5/SHA) - you can quickly assess whether an activity is harmless or a genuine threat [17][19]. This extra layer of context bridges the gap between isolated data points and comprehensive threat detection.
Adding context to logs allows your security team to adjust the severity of events based on real-world risks. For example, a low-priority alert about an EC2 instance accessing an uncommon domain might escalate to high-priority if threat intelligence reveals the domain is tied to a known command-and-control server [1].
"The context in which the alert happened determines its true criticality" – AWS Well-Architected Framework [1]
This approach not only enhances threat detection but also eases the workload for analysts. Automating data correlation reduces manual effort and speeds up incident responses, making automation a key element of this process.
With unified and correlated logs as a base, external threat intelligence helps validate anomalies. However, despite its advantages, 38% of organisations still rely on manual methods for aggregating and analysing threat intelligence [17]. Given the sheer volume of indicators, automating the comparison of log entries against threat databases in real time is essential [17]. For high-confidence matches - like traffic to ransomware-associated domains or Tor exit nodes - you can even trigger automatic blocking to neutralise threats before they escalate [17].
To make this process effective, standardise log fields across systems. This ensures that IP addresses, domain names, and other indicators align correctly with threat feeds [19]. Use confidence scores to minimise the risk of blocking legitimate traffic [17]. Additionally, enrich your logs with extra details, such as GeoIP data to spot unusual locations, WHOIS information to verify domain ownership, and internal Active Directory data to link activities to specific users and assess their risk levels [18]. Combining external threat intelligence with internal business context creates a strong foundation for identifying and addressing complex attack patterns.
Tools like LogCentral can simplify this process. By integrating threat intelligence feeds directly into your log correlation workflow, these tools help you detect threats faster while ensuring GDPR compliance for European operations. This enriched data not only strengthens threat detection but also supports secure storage, retention, and regular review as part of your overall log management strategy.
7. Ensure Secure Storage, Retention, and Regular Review
Start by securing your logs the moment they’re collected. Use AES-256 encryption for data at rest and TLS 1.3 for data in transit to guard against unauthorised access during both storage and transmission. To maintain the integrity of your logs - especially during forensic investigations - implement immutable storage that prevents any tampering. Given that malware can lurk undetected for 70–200 days and some incidents take up to 18 months to uncover [3], retaining logs for the long term is critical.
Control access to logs with Role-Based Access Control (RBAC), enforce digital signatures, and perform regular checksum verifications to detect any tampering. For example, Microsoft retains standard audit logs for Microsoft 365 users for 180 days and keeps internal security logs for up to two years to support forensic needs [7]. Additionally, organisations under GDPR must maintain logs that allow for detailed incident analysis to comply with the regulation’s 72-hour breach notification requirement [21].
"Security log retention is not just a compliance checkbox - it's a strategic investment in operational resilience." – Microsoft [20]
Beyond secure storage, it’s equally important to refine your correlation rules. A monthly review of these rules [4] can significantly improve efficiency. For instance, filtering out irrelevant event codes can cut log collection volumes by over 50%. Meanwhile, implementing data tiering can reduce storage costs by 30% to 80% [4]. These efforts help minimise alert fatigue and improve the accuracy of alerts, allowing your security team to focus on real threats instead of wasting time on false positives.
Tools like LogCentral make this process easier. With features like built-in GDPR compliance through EU-based hosting, configurable long-term retention, and native RBAC for user management, LogCentral ensures your data stays secure and compliant. It also supports scalable retention policies tailored to your needs, completing the security loop and keeping your log correlation both effective and regulation-ready.
Comparison Table
European businesses need to carefully weigh GDPR compliance, multi-tenancy, and retention policies when choosing a log management platform. Missteps in these areas can lead to compliance issues and higher costs. Here's a breakdown of key features across leading platforms:
| Feature | LogCentral | Splunk | Elastic Stack |
|---|---|---|---|
| GDPR Compliance | Yes (EU hosting by default) | Yes (compliance reports/EU options) | Yes (flexible deployment/EU clouds) |
| Multi-Tenancy | Native (built for MSPs) | Yes (enterprise-grade/complex) | Yes (Kibana Spaces/RBAC) |
| Alerting | Intelligent real-time alerts; colour-coded visualisation | AI/ML-driven (ITSI); automated anomaly detection | Attack Discovery; prebuilt detection rules; ML-driven |
| Monitoring Focus | Syslog, Cisco Meraki, smart IP management | Full-stack observability, APM, synthetics | Endpoint, cloud, network, APM, synthetics |
| Retention | 1 year on all plans | Configurable/variable | Tiered (Hot to Frozen) via ILM |
LogCentral stands out for its straightforward GDPR compliance through default EU hosting and its native multi-tenancy, designed specifically for MSPs. With a consistent 1-year data retention policy across all plans, it simplifies budgeting and operational planning. This makes it a strong choice for European businesses that prioritise regulatory compliance and need a user-friendly solution without the added complexity of enterprise-grade tools.
On the other hand, Splunk and Elastic Stack cater to larger enterprises with advanced features like full-stack observability and AI-driven anomaly detection. Elastic Stack’s tiered data storage can cut costs by 30%–80%[4], while Splunk’s ITSI uses machine learning to predict incidents before they escalate. These platforms are ideal for organisations needing advanced observability across endpoints, networks, and applications.
For mid-sized businesses and MSPs focused on security monitoring and GDPR compliance, LogCentral offers a practical, streamlined option. Meanwhile, Splunk and Elastic Stack provide the depth and scalability required for larger enterprises handling complex monitoring needs. This comparison highlights how selecting the right platform depends on balancing regulatory priorities with operational requirements.
Conclusion
The practices we've covered work together to build a strong and effective security framework. These seven methods transform log correlation from a reactive process into a proactive approach to security. By standardising log formats, you can ensure consistent detection rules across your entire system. Centralising log collection and automating the normalisation process create a unified perspective, helping to uncover intricate attack patterns instead of overwhelming analysts with isolated alerts.
Using machine learning to define correlation rules and focusing on key log sources helps cut down on false positives. Additionally, filtering out unnecessary event codes reduces the volume of logs, allowing security teams to concentrate on real threats. This aligns with the broader goal of improving efficiency and accuracy.
Incorporating threat intelligence adds crucial context, helping to differentiate between routine administrative actions and genuine threats based on factors like user roles, geolocation, and the value of assets. Secure log storage with tiered retention not only meets compliance standards but also helps control costs by reducing storage expenses.
For businesses in Europe, GDPR compliance is a critical concern. Tools like LogCentral address these needs by offering intelligent alerts and live visualisation, enabling teams to identify threats quickly while avoiding the usual complexity of enterprise-level solutions.
These combined practices lead to faster response times, better threat detection, and a more resilient security posture. Whether you're an IT team or an MSP managing multiple clients, adopting these methods can result in measurable improvements in both operational efficiency and overall security.
FAQs
Which logs should I prioritise first for security correlation?
To stay on top of potential threats, it's crucial to focus on logs from critical systems. These include authentication servers, network devices, firewalls, and security appliances. Why? Because these logs provide key insights into suspicious activities or unauthorised access attempts. By analysing them, you can enhance your ability to detect and respond to security threats effectively.
How can I reduce false positives without missing real attacks?
To reduce false positives and accurately identify real threats, event correlation techniques are key. These methods examine log data across your network to uncover attack patterns and connections, boosting both detection precision and response times. Tools such as LogCentral provide advanced capabilities to refine log correlation and simplify security monitoring, making them a valuable resource for IT teams and businesses, no matter their size.
How long should I retain logs to meet GDPR and investigation needs?
To align with GDPR and meet investigation requirements, it's crucial to retain logs only for the time they are needed. The retention period varies based on the type of log. For example, security logs are often kept for about 90 days, while financial logs might need to be stored for as long as six years. Tools such as LogCentral can simplify this process by automating retention policies and ensuring both compliance and effective log management.